 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAge Invariant Face Recognition
Age-invariant face recognition is the process of identifying and verifying individuals across different age groups.
Papers and Code
From Age Estimation to Age-Invariant Face Recognition: Generalized Age Feature Extraction Using Order-Enhanced Contrastive Learning
Jan 03, 2025



Generalized age feature extraction is crucial for age-related facial analysis tasks, such as age estimation and age-invariant face recognition (AIFR). Despite the recent successes of models in homogeneous-dataset experiments, their performance drops significantly in cross-dataset evaluations. Most of these models fail to extract generalized age features as they only attempt to map extracted features with training age labels directly without explicitly modeling the natural progression of aging. In this paper, we propose Order-Enhanced Contrastive Learning (OrdCon), which aims to extract generalized age features to minimize the domain gap across different datasets and scenarios. OrdCon aligns the direction vector of two features with either the natural aging direction or its reverse to effectively model the aging process. The method also leverages metric learning which is incorporated with a novel soft proxy matching loss to ensure that features are positioned around the center of each age cluster with minimum intra-class variance. We demonstrate that our proposed method achieves comparable results to state-of-the-art methods on various benchmark datasets in homogeneous-dataset evaluations for both age estimation and AIFR. In cross-dataset experiments, our method reduces the mean absolute error by about 1.38 in average for age estimation task and boosts the average accuracy for AIFR by 1.87%.
Unmasking the Uniqueness: A Glimpse into Age-Invariant Face Recognition of Indigenous African Faces
Aug 13, 2024The task of recognizing the age-separated faces of an individual, Age-Invariant Face Recognition (AIFR), has received considerable research efforts in Europe, America, and Asia, compared to Africa. Thus, AIFR research efforts have often under-represented/misrepresented the African ethnicity with non-indigenous Africans. This work developed an AIFR system for indigenous African faces to reduce the misrepresentation of African ethnicity in facial image analysis research. We adopted a pre-trained deep learning model (VGGFace) for AIFR on a dataset of 5,000 indigenous African faces (FAGE\_v2) collected for this study. FAGE\_v2 was curated via Internet image searches of 500 individuals evenly distributed across 10 African countries. VGGFace was trained on FAGE\_v2 to obtain the best accuracy of 81.80\%. We also performed experiments on an African-American subset of the CACD dataset and obtained the best accuracy of 91.5\%. The results show a significant difference in the recognition accuracies of indigenous versus non-indigenous Africans.
Synthetic Face Ageing: Evaluation, Analysis and Facilitation of Age-Robust Facial Recognition Algorithms
Jun 10, 2024



The ability to accurately recognize an individual's face with respect to human aging factor holds significant importance for various private as well as government sectors such as customs and public security bureaus, passport office, and national database systems. Therefore, developing a robust age-invariant face recognition system is of crucial importance to address the challenges posed by ageing and maintain the reliability and accuracy of facial recognition technology. In this research work, the focus is to explore the feasibility of utilizing synthetic ageing data to improve the robustness of face recognition models that can eventually help in recognizing people at broader age intervals. To achieve this, we first design set of experiments to evaluate state-of-the-art synthetic ageing methods. In the next stage we explore the effect of age intervals on a current deep learning-based face recognition algorithm by using synthetic ageing data as well as real ageing data to perform rigorous training and validation. Moreover, these synthetic age data have been used in facilitating face recognition algorithms. Experimental results show that the recognition rate of the model trained on synthetic ageing images is 3.33% higher than the results of the baseline model when tested on images with an age gap of 40 years, which prove the potential of synthetic age data which has been quantified to enhance the performance of age-invariant face recognition systems.
Cross-Age Contrastive Learning for Age-Invariant Face Recognition
Jan 02, 2024



Cross-age facial images are typically challenging and expensive to collect, making noise-free age-oriented datasets relatively small compared to widely-used large-scale facial datasets. Additionally, in real scenarios, images of the same subject at different ages are usually hard or even impossible to obtain. Both of these factors lead to a lack of supervised data, which limits the versatility of supervised methods for age-invariant face recognition, a critical task in applications such as security and biometrics. To address this issue, we propose a novel semi-supervised learning approach named Cross-Age Contrastive Learning (CACon). Thanks to the identity-preserving power of recent face synthesis models, CACon introduces a new contrastive learning method that leverages an additional synthesized sample from the input image. We also propose a new loss function in association with CACon to perform contrastive learning on a triplet of samples. We demonstrate that our method not only achieves state-of-the-art performance in homogeneous-dataset experiments on several age-invariant face recognition benchmarks but also outperforms other methods by a large margin in cross-dataset experiments.
Robust Sclera Segmentation for Skin-tone Agnostic Face Image Quality Assessment
Dec 22, 2023Face image quality assessment (FIQA) is crucial for obtaining good face recognition performance. FIQA algorithms should be robust and insensitive to demographic factors. The eye sclera has a consistent whitish color in all humans regardless of their age, ethnicity and skin-tone. This work proposes a robust sclera segmentation method that is suitable for face images in the enrolment and the border control face recognition scenarios. It shows how the statistical analysis of the sclera pixels produces features that are invariant to skin-tone, age and ethnicity and thus can be incorporated into FIQA algorithms to make them agnostic to demographic factors.
When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework and A New Benchmark
Oct 17, 2022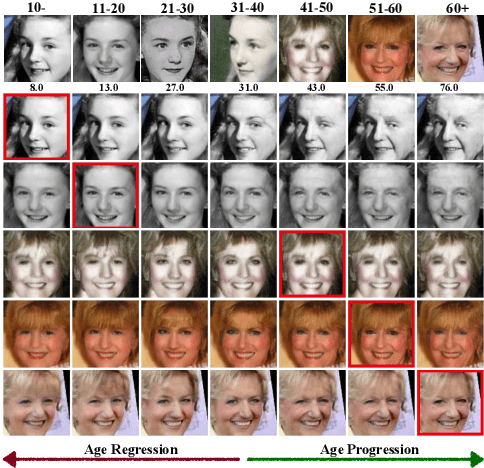

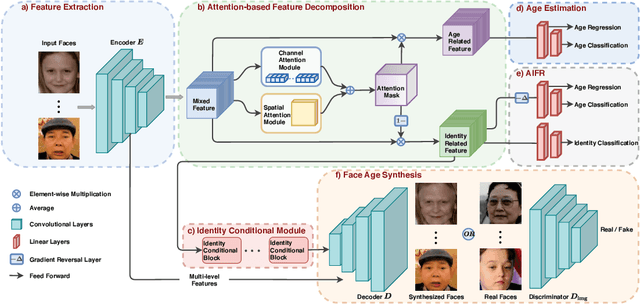
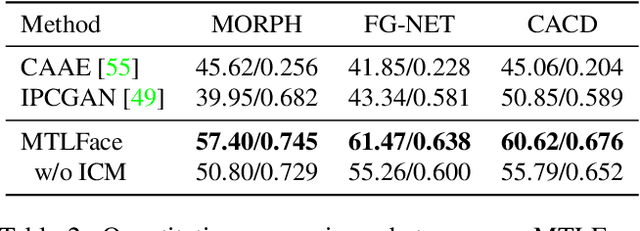
To minimize the impact of age variation on face recognition, age-invariant face recognition (AIFR) extracts identity-related discriminative features by minimizing the correlation between identity- and age-related features while face age synthesis (FAS) eliminates age variation by converting the faces in different age groups to the same group. However, AIFR lacks visual results for model interpretation and FAS compromises downstream recognition due to artifacts. Therefore, we propose a unified, multi-task framework to jointly handle these two tasks, termed MTLFace, which can learn the age-invariant identity-related representation for face recognition while achieving pleasing face synthesis for model interpretation. Specifically, we propose an attention-based feature decomposition to decompose the mixed face features into two uncorrelated components -- identity- and age-related features -- in a spatially constrained way. Unlike the conventional one-hot encoding that achieves group-level FAS, we propose a novel identity conditional module to achieve identity-level FAS, which can improve the age smoothness of synthesized faces through a weight-sharing strategy. Benefiting from the proposed multi-task framework, we then leverage those high-quality synthesized faces from FAS to further boost AIFR via a novel selective fine-tuning strategy. Furthermore, to advance both AIFR and FAS, we collect and release a large cross-age face dataset with age and gender annotations, and a new benchmark specifically designed for tracing long-missing children. Extensive experimental results on five benchmark cross-age datasets demonstrate that MTLFace yields superior performance for both AIFR and FAS. We further validate MTLFace on two popular general face recognition datasets, obtaining competitive performance on face recognition in the wild. Code is available at http://hzzone.github.io/MTLFace.
Age-Invariant Face Embedding using the Wasserstein Distance
May 04, 2023In this work, we study face verification in datasets where images of the same individuals exhibit significant age differences. This poses a major challenge for current face recognition and verification techniques. To address this issue, we propose a novel approach that utilizes multitask learning and a Wasserstein distance discriminator to disentangle age and identity embeddings of facial images. Our approach employs multitask learning with a Wasserstein distance discriminator that minimizes the mutual information between the age and identity embeddings by minimizing the Jensen-Shannon divergence. This improves the encoding of age and identity information in face images and enhances the performance of face verification in age-variant datasets. We evaluate the effectiveness of our approach using multiple age-variant face datasets and demonstrate its superiority over state-of-the-art methods in terms of face verification accuracy.
Localization using Multi-Focal Spatial Attention for Masked Face Recognition
May 03, 2023
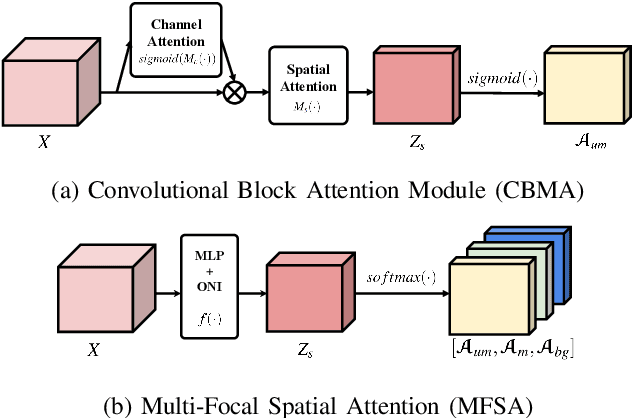
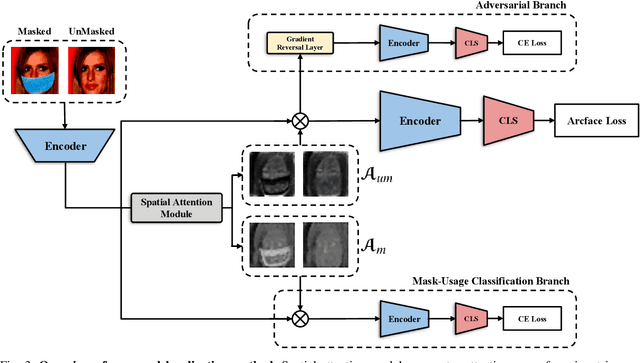
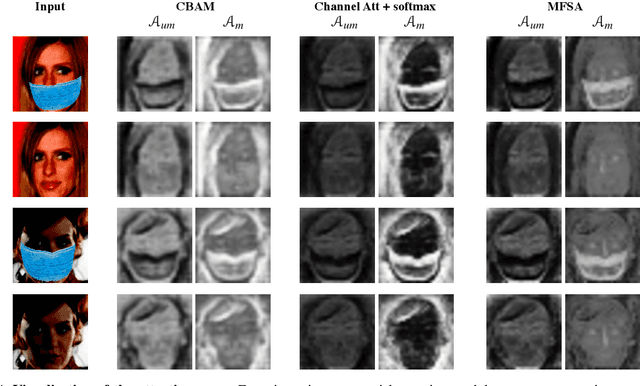
Since the beginning of world-wide COVID-19 pandemic, facial masks have been recommended to limit the spread of the disease. However, these masks hide certain facial attributes. Hence, it has become difficult for existing face recognition systems to perform identity verification on masked faces. In this context, it is necessary to develop masked Face Recognition (MFR) for contactless biometric recognition systems. Thus, in this paper, we propose Complementary Attention Learning and Multi-Focal Spatial Attention that precisely removes masked region by training complementary spatial attention to focus on two distinct regions: masked regions and backgrounds. In our method, standard spatial attention and networks focus on unmasked regions, and extract mask-invariant features while minimizing the loss of the conventional Face Recognition (FR) performance. For conventional FR, we evaluate the performance on the IJB-C, Age-DB, CALFW, and CPLFW datasets. We evaluate the MFR performance on the ICCV2021-MFR/Insightface track, and demonstrate the improved performance on the both MFR and FR datasets. Additionally, we empirically verify that spatial attention of proposed method is more precisely activated in unmasked regions.
Deep Adaptation of Adult-Child Facial Expressions by Fusing Landmark Features
Sep 18, 2022
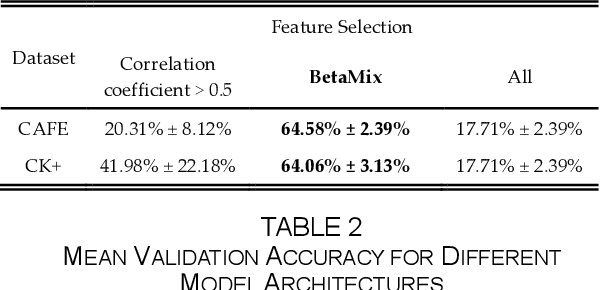

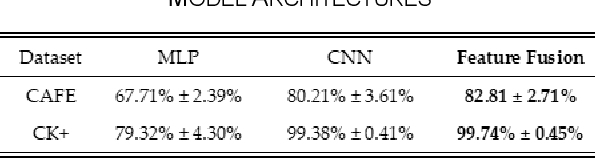
Imaging of facial affects may be used to measure psychophysiological attributes of children through their adulthood, especially for monitoring lifelong conditions like Autism Spectrum Disorder. Deep convolutional neural networks have shown promising results in classifying facial expressions of adults. However, classifier models trained with adult benchmark data are unsuitable for learning child expressions due to discrepancies in psychophysical development. Similarly, models trained with child data perform poorly in adult expression classification. We propose domain adaptation to concurrently align distributions of adult and child expressions in a shared latent space to ensure robust classification of either domain. Furthermore, age variations in facial images are studied in age-invariant face recognition yet remain unleveraged in adult-child expression classification. We take inspiration from multiple fields and propose deep adaptive FACial Expressions fusing BEtaMix SElected Landmark Features (FACE-BE-SELF) for adult-child facial expression classification. For the first time in the literature, a mixture of Beta distributions is used to decompose and select facial features based on correlations with expression, domain, and identity factors. We evaluate FACE-BE-SELF on two pairs of adult-child data sets. Our proposed FACE-BE-SELF approach outperforms adult-child transfer learning and other baseline domain adaptation methods in aligning latent representations of adult and child expressions.
ChildPredictor: A Child Face Prediction Framework with Disentangled Learning
Apr 21, 2022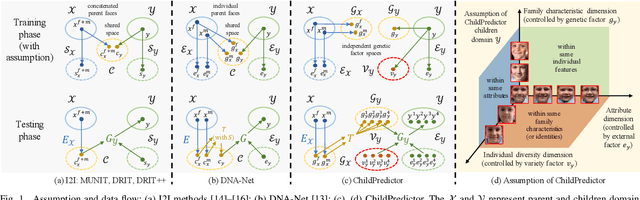

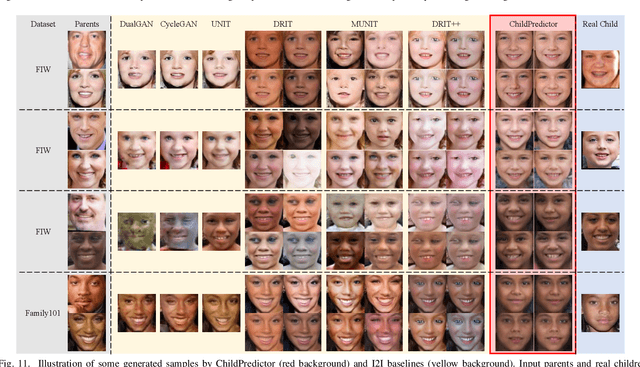

The appearances of children are inherited from their parents, which makes it feasible to predict them. Predicting realistic children's faces may help settle many social problems, such as age-invariant face recognition, kinship verification, and missing child identification. It can be regarded as an image-to-image translation task. Existing approaches usually assume domain information in the image-to-image translation can be interpreted by "style", i.e., the separation of image content and style. However, such separation is improper for the child face prediction, because the facial contours between children and parents are not the same. To address this issue, we propose a new disentangled learning strategy for children's face prediction. We assume that children's faces are determined by genetic factors (compact family features, e.g., face contour), external factors (facial attributes irrelevant to prediction, such as moustaches and glasses), and variety factors (individual properties for each child). On this basis, we formulate predictions as a mapping from parents' genetic factors to children's genetic factors, and disentangle them from external and variety factors. In order to obtain accurate genetic factors and perform the mapping, we propose a ChildPredictor framework. It transfers human faces to genetic factors by encoders and back by generators. Then, it learns the relationship between the genetic factors of parents and children through a mapping function. To ensure the generated faces are realistic, we collect a large Family Face Database to train ChildPredictor and evaluate it on the FF-Database validation set. Experimental results demonstrate that ChildPredictor is superior to other well-known image-to-image translation methods in predicting realistic and diverse child faces. Implementation codes can be found at https://github.com/zhaoyuzhi/ChildPredictor.